Все гайды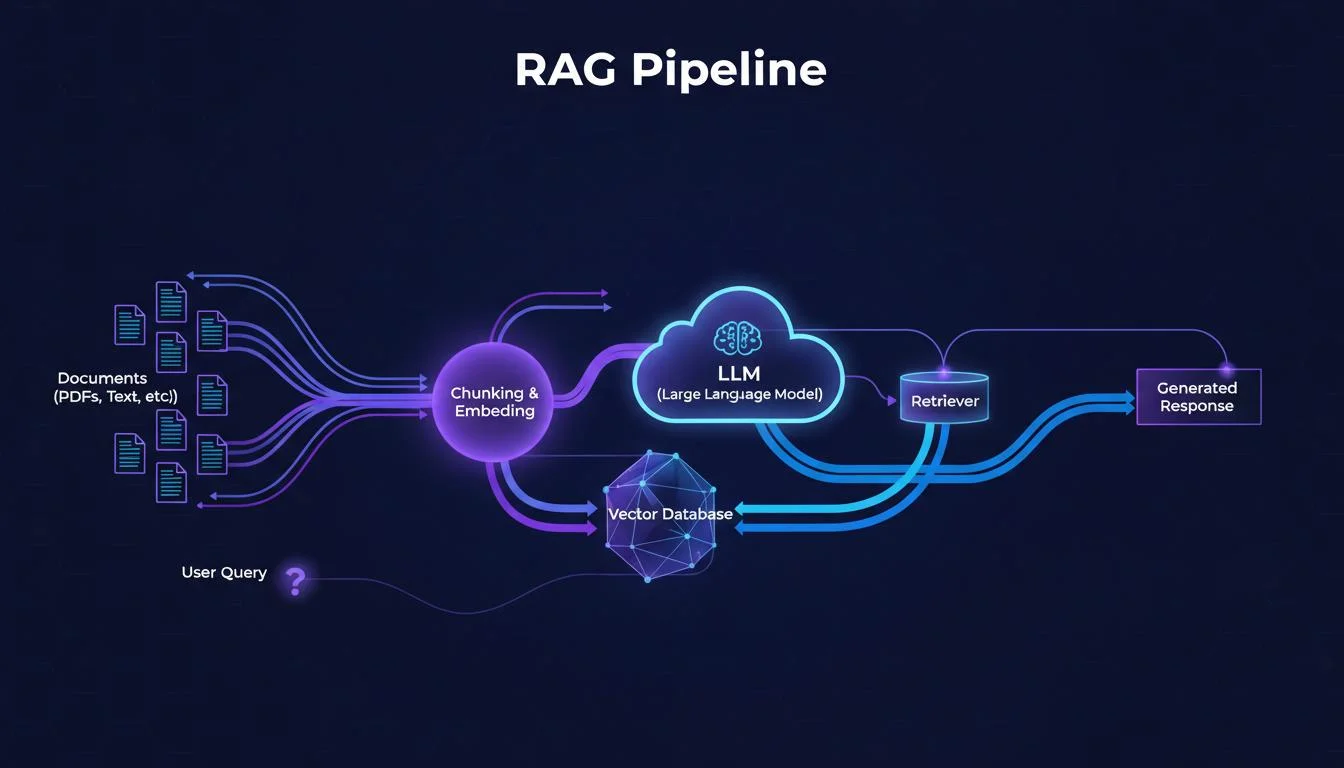
Средний25 мин
Как настроить RAG-пайплайн с LangChain и ChromaDB
Пошаговое руководство по созданию системы retrieval-augmented generation
## Введение
RAG (Retrieval-Augmented Generation) позволяет LLM отвечать на вопросы на основе ваших документов. В этом гайде мы соберём полный пайплайн.
## Шаг 1: Установка зависимостей
```bash
pip install langchain chromadb openai
```
## Шаг 2: Загрузка документов
```python
from langchain.document_loaders import DirectoryLoader
loader = DirectoryLoader('docs/', glob="**/*.md")
docs = loader.load()
```
## Шаг 3: Разбиение на чанки
```python
from langchain.text_splitter import RecursiveCharacterTextSplitter
splitter = RecursiveCharacterTextSplitter(chunk_size=500, chunk_overlap=50)
chunks = splitter.split_documents(docs)
```
## Шаг 4: Создание векторного хранилища
```python
from langchain.embeddings import OpenAIEmbeddings
from langchain.vectorstores import Chroma
embeddings = OpenAIEmbeddings()
db = Chroma.from_documents(chunks, embeddings, persist_directory="./chroma_db")
```
## Шаг 5: Сборка цепочки
```python
from langchain.chains import RetrievalQA
from langchain.llms import OpenAI
qa = RetrievalQA.from_chain_type(
llm=OpenAI(),
chain_type="stuff",
retriever=db.as_retriever(search_kwargs={"k": 3})
)
print(qa.run("Как настроить окружение?"))
```
## Оптимизации
• Используйте hybrid search (BM25 + semantic)
• Добавьте re-ranking с cross-encoder
• Кэшируйте частые запросы